Hyperparameter Search: Adaptive (Asynchronous)¶
The state-of-the-art adaptive_asha search method employs the same
underlying algorithm as the Adaptive (Advanced) method, but it uses an
asynchronous version of successive halving (ASHA), which is more suitable for
large-scale experiments with hundreds or thousands of trials.
Quick start¶
Here are some suggested initial settings for adaptive_asha that
typically work well.
Search mode:
mode: Set tostandard.
Resource budget:
max_length: The maximum training length (see Training Units) of any trial that survives to the end of the experiment. This quantity is domain-specific and should roughly reflect the number of minibatches the model must be trained on for it to converge on the data set. For users who would like to determine this number experimentally, train a model with reasonable hyperparameters using thesinglesearch method.max_trials: This indicates the total number of hyperparameter settings that will be evaluated in the experiment. Setmax_trialsto at least 500 to take advantage of speedups from early-stopping. You can also set a largemax_trialsand stop the experiment once the desired performance is achieved.max_concurrent_trials: This field controls the degree of parallelism of the experiment. The experiment will have a maximum of this many trials training simultaneously at any one time. Theadaptive_ashasearcher scales nearly perfectly with additional compute, so you should set this field based on compute environment constraints.
Details¶
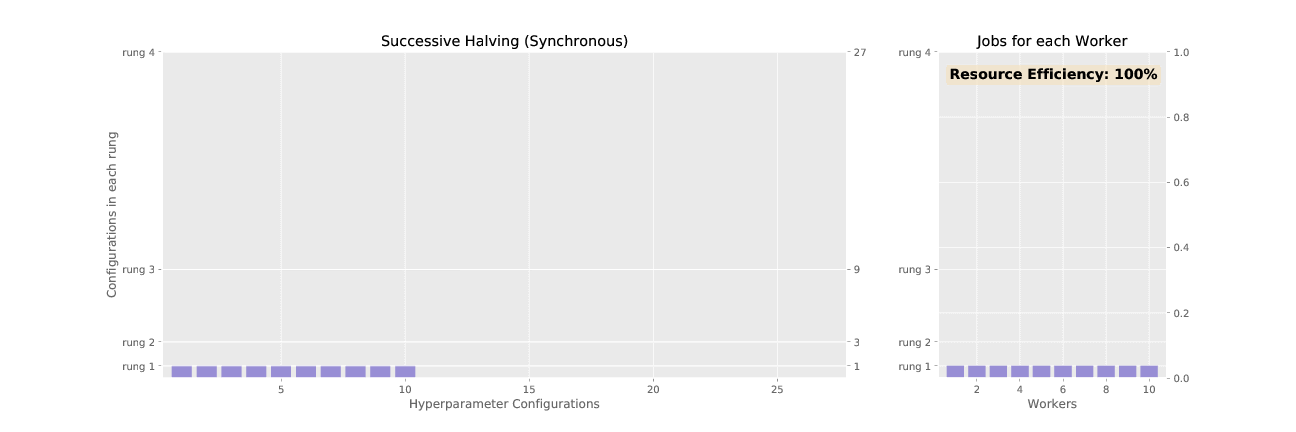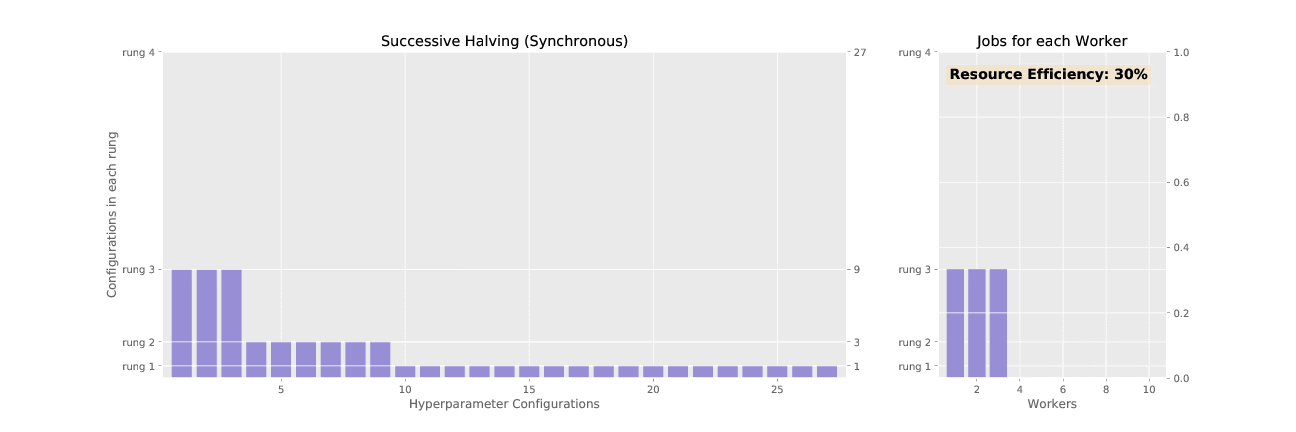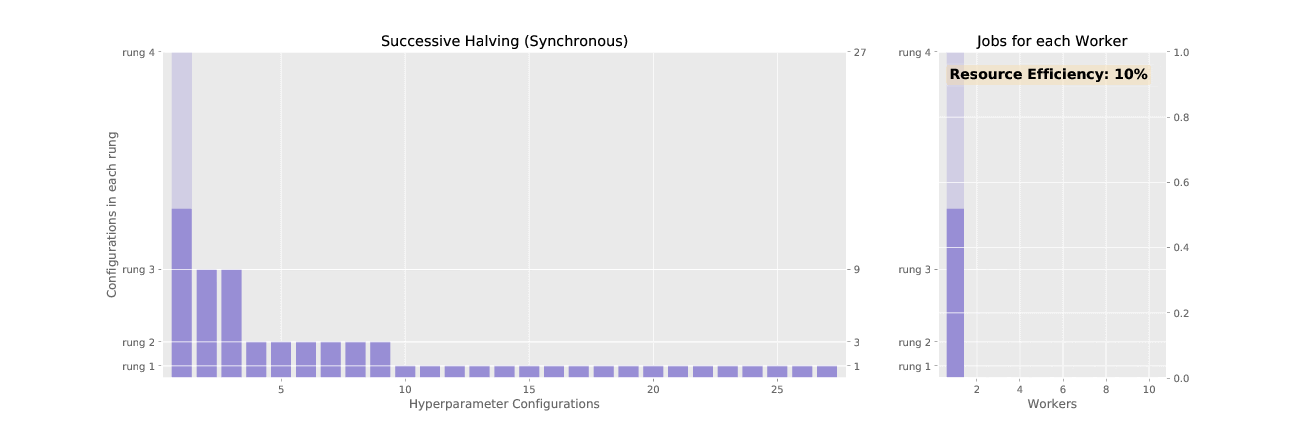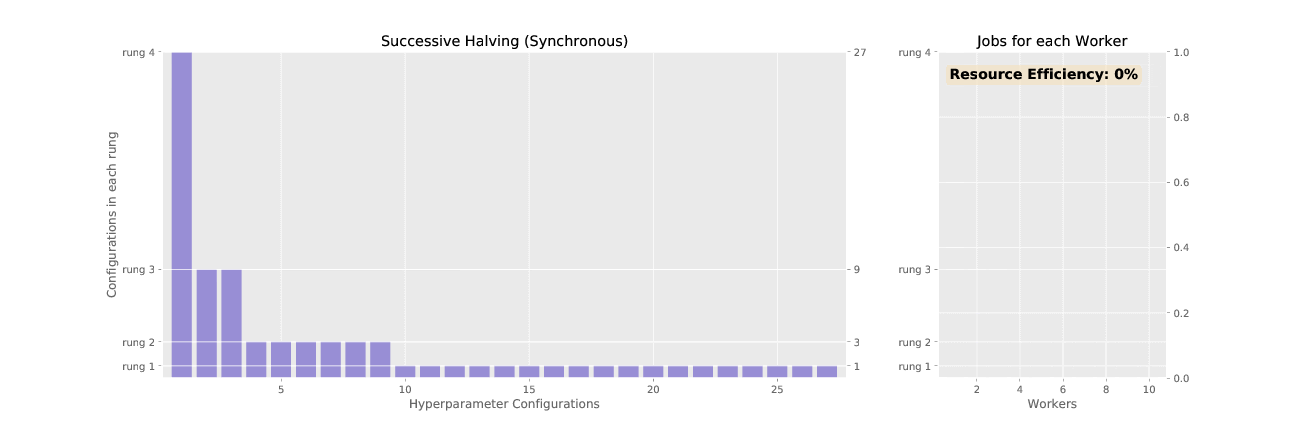
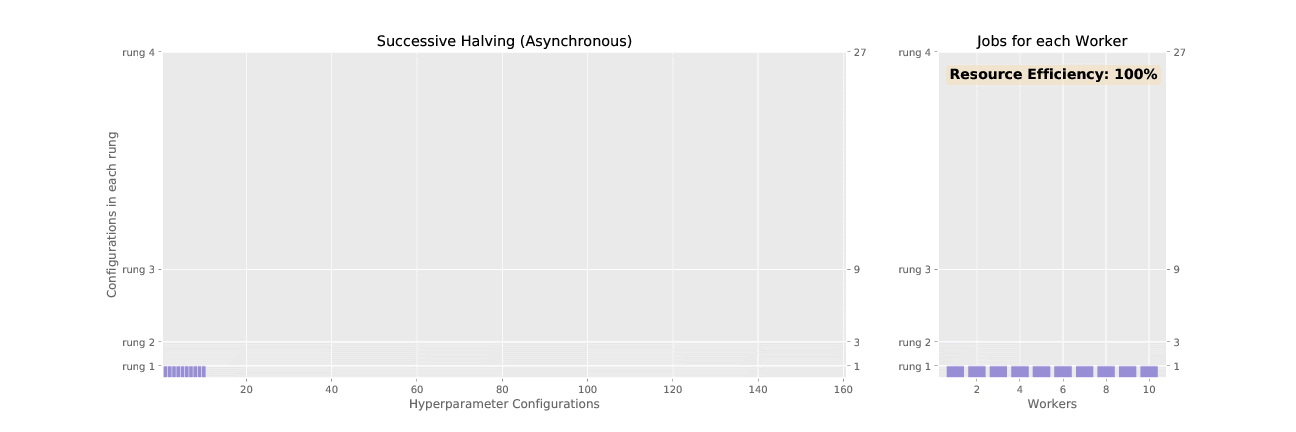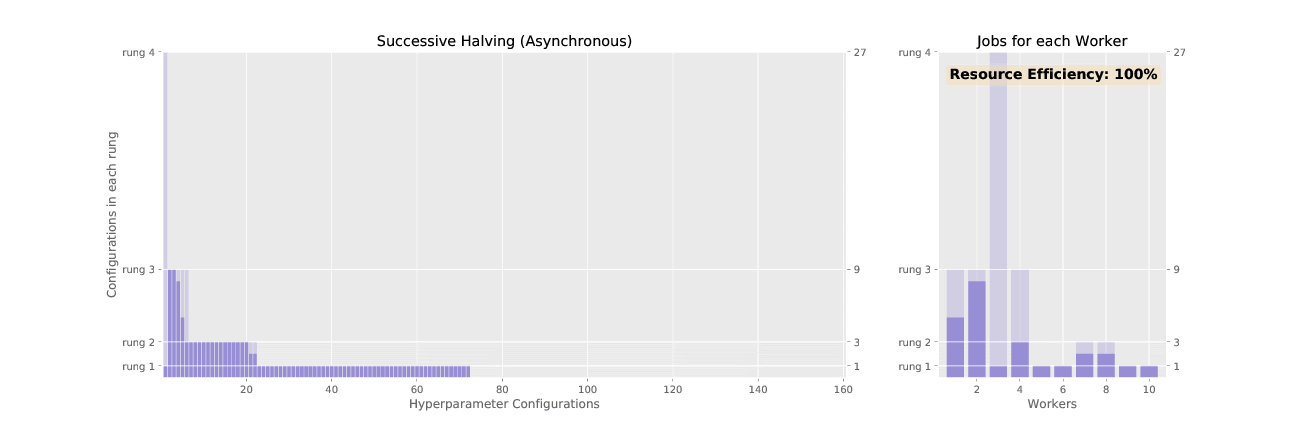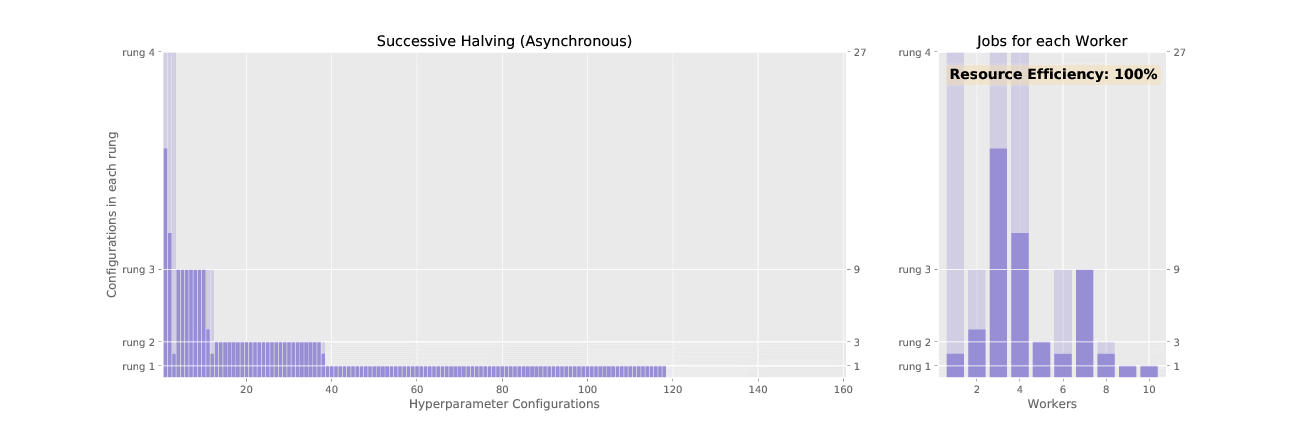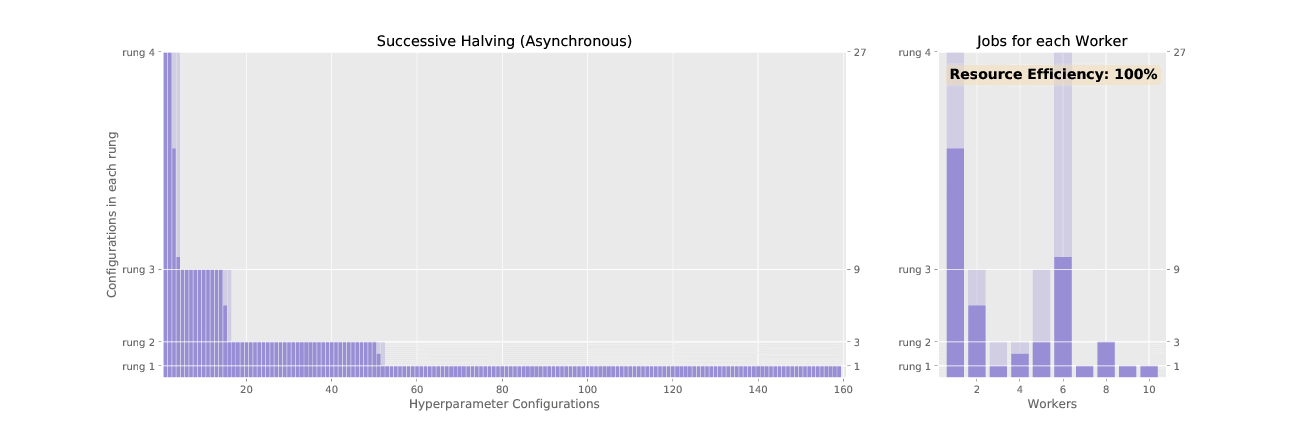
Adaptive (ASHA) is an approximation to the resource allocation scheme used by Adaptive. While Adaptive promotes hyperparameter configurations synchronously, resulting in underutilized nodes waiting on completion of validation steps for other configurations, ASHA uses asynchronous promotions to maximize compute efficiency of the searcher.
See the difference in asynchronous vs. sychronous promotions in the two animated GIFs below: